オペラント条件づけ
operant conditioning / instrumental conditioning
Skinner
今回は超重要、最頻出のオペラント条件づけです。
この条件づけに関する細かい概念はそれぞれ別記事で扱う予定です。
まず、オペラント条件づけについての大まかな説明をします。
これは、スキナーによって提唱された学習心理学のひとつ、条件づけ学習です。条件づけ学習には大きく二種類あるのですが、このほかに古典的条件づけ(レスポンデント条件づけ)があります。これはレスポンデント条件づけという記事で扱いますので、今回は名前の紹介だけ。
オペラント条件づけは別名道具的条件づけと呼ばれますが、どちらでも構いません。一応、オペラント条件づけの方が主流とされていますが、意味は変わりません。
しいて言うなら、最初は道具を使った学習として道具的条件づけと呼ばれることが多かった学習過程ですが、受け身的な意味合いを含む「レスポンデント条件づけ」との対比として、オペラント(自発的な)条件づけという言葉が主流となりました。
オペラント条件づけは、スキナー箱の実験が有名ですが、実験の対象となる有機体がある行動を行ったときに報酬や罰を与えることによって、その行動の自発的な生起頻度を変化させる過程のことを指します。
ではオペラント条件づけの定義です。この説明をより簡潔にしたものです。
「動物(ヒト)が自発した反応に対する強化の随伴によって、その自発頻度を変化させる」過程
もう少し詳しくいうと、「動物(ヒト)が自由な環境の中で様々なオペラント行動を自発しているうちに、それが報酬などの結果を得て、そのことによって当該のオペラント行動の自発頻度が上昇する過程」です。
このオペラント行動というのは、自発して行うもので、この行動に焦点を当てた条件づけ学習である点が、レスポンデント条件づけとの大きな違いです。
ではこのオペラント行動とは、どのような行動のことをさすかというと、有機体の行動レパートリーに含まれているものでなければならないということです。
簡単に言うと、犬にどのような条件づけ学習を行ってもヒトの言語を習得することはできない、ということですね。
この考えを頭に入れたところで、オペラント条件づけの定説について紹介します。
「有機体の行動レパートリーに含まれ得るもので、自発できる随意反応であれば、直後強化と漸次的接近法を用いて、どのような反応でも条件づけることが可能である」
これが定説となっています。ここで新たなワード、強化と漸次的接近法というワードが出てきました。
これについて、詳しくみていこうと思います。
強化について、強化とは、このオペラント条件づけ学習の原理を成すものです。漸次的接近法については、シェイピングなどで扱います。心理学において幅広く用いられており、臨床心理学や、学習心理学などでこの単語を見かけるでしょう。
この強化の考え方は、ソーンダイク(Thorndike)の「効果の法則」、新行動主義者ハル(Hull)の「強化」も同じ原理に基づいています。
原理
- 強化随伴性、三項随伴性(three term contingency)
- 強化(reinforcement)、強化子(reinforcer)
- 部分強化、間歇強化(partial reinforcement)
順に説明します。
強化随伴性、三項随伴性
three term contingency
これは、強化に随伴して行動が起こり、更に自発的な行動が減増する、これらの流れは随伴している、という考え方です。S-R-S理論ともいわれており、Sは弁別刺激、Rはオペラント反応、Sは強化刺激を指します。

この刺激性制御とは、刺激の有無や変化によって反応がどう変わるか、を見ようとするものです、弁別学習、弁別訓練のトピックが典型です。
強化スケジュールについては、部分強化、間歇強化で扱う予定です。
強化と罰
強化についての説明はおそらくこれを読んでいる方たちなら説明は不要かと思いますが、強化と罰の関係についての表を載せておきます。
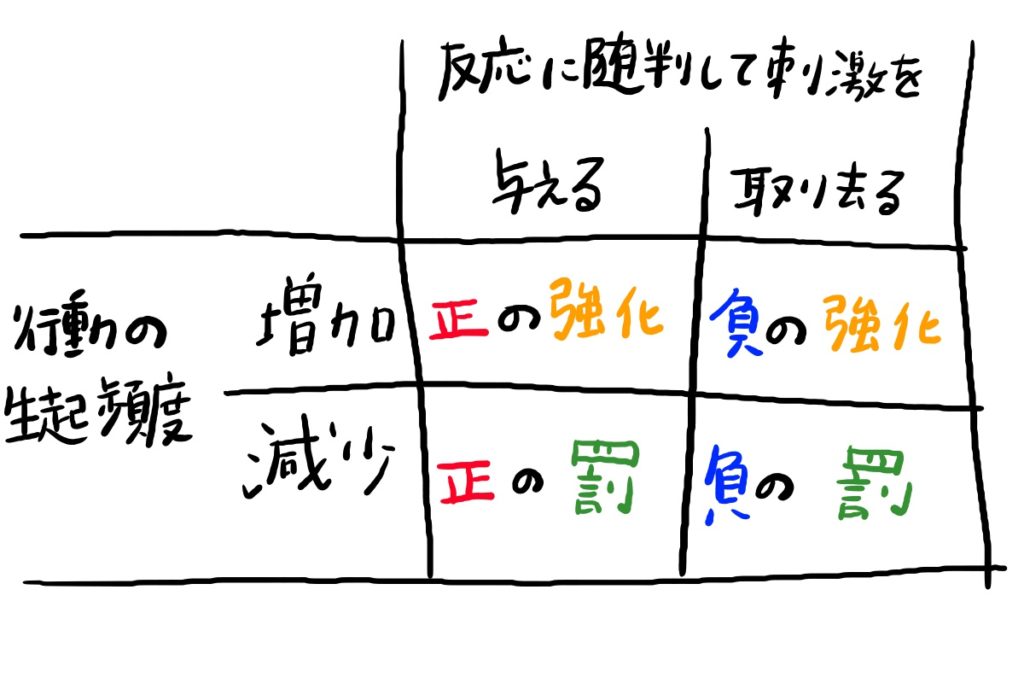
この表は丸暗記かつアウトプットの練習を何度もしておいてください。
負の罰は、除外訓練、省略訓練、オミッション訓練などの文面があれば、負の罰と思っていただいて構いません。
部分強化、間歇強化は個別で記事にする予定ですので、そちらを参照してください。
ベースライン
その他のワードとしてベースラインについて軽く触れておきます。
行動の自発頻度と強化との関連を検討するのがオペラント条件づけの基本的枠組みですが、目標とする行動の自発頻度をあらかじめ測定するために基準作成を行います。これがベースラインです。
そこまで重要ではありませんが一応紹介しておきました。
オペラント条件づけはとても大きなテーマのため、細かく個別に記事を作成する予定です。
- 条件性強化子
- シェイピング
- 強化スケジュール
- プレマックの原理
- 反応制限説
- 行動調整説
- 逃避条件づけ
- 学習性無力感
- 無誤弁別学習
- 行動対比
- 頂点移動
これらについては、今後個別で更新する予定ですのでしばらくお待ちください。